Un modelo de lenguaje puede escribir código complejo, resolver ecuaciones diferenciales y discutir sobre la influencia de Borges en la literatura contemporánea. Pero si le mostrás un patrón visual simple que no vio antes y le pedís que lo complete, el sistema falla.
¿Por qué algo que domina la sintaxis de la programación no puede resolver rompecabezas que un nene de ocho años descifra en minutos? La respuesta no está en la falta de conocimiento, sino en la arquitectura de su procesamiento. Como explicaba en un post anterior, los LLMs predicen la siguiente palabra basándose en la geometría de todas las anteriores. Es anticipación estadística, no una “deliberación lógica”: maestros de la predicción mas que navegantes con brújula.
El espejismo del razonamiento
La publicación en 2022 de un paper titulado “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” fue clave. La premisa era simple: si le pedimos a un modelo que “piense paso a paso” antes de dar una respuesta, su rendimiento en problemas lógicos mejora drásticamente. Eso permitió que problemas matemáticos en los que antes fallaba se podían resolver. Pero un investigador en inteligencia artificial, François Chollet, planteó también una distinción importante, que mostrar pasos de razonamiento no es lo mismo que razonar.
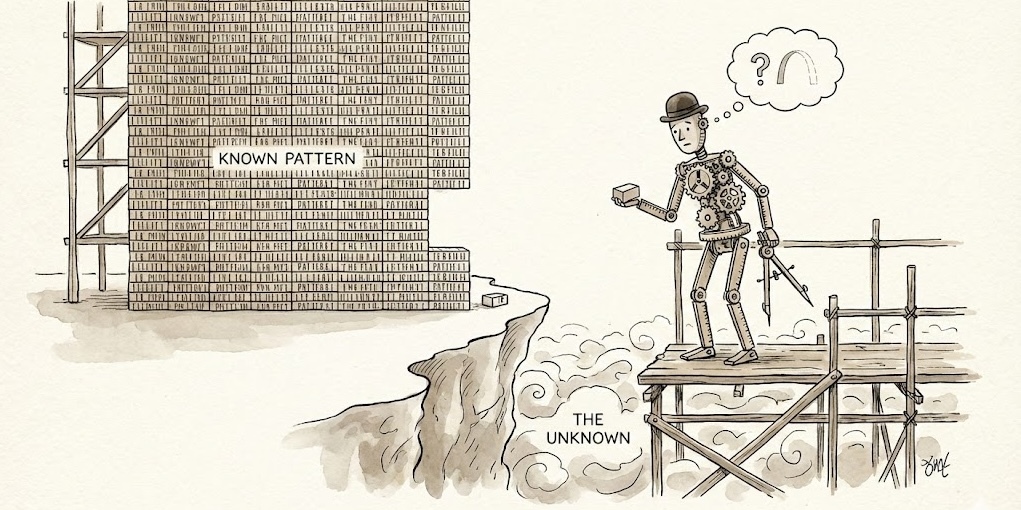
A nivel fundamental, los LLMs actuales operan como almacenes de plantillas memorizadas de inmensa capacidad. Cuando les preguntás cómo resolver una ecuación lineal, no deducen la respuesta desde primeros principios; recuperan una plantilla probabilística que vieron miles de veces durante su entrenamiento y la ejecutan. Funcionan brillantemente mientras el problema sea familiar. Pero cuando la tarea es genuinamente nueva (algo para lo que no tienen una plantilla guardada), el sistema encuentra su límite.
Interpolación vs. extrapolación
Chollet creó un benchmark llamado ARC (Abstraction and Reasoning Corpus) para medir exactamente esta diferencia: la capacidad de resolver problemas nuevos a partir de muy pocos ejemplos. Los humanos resolvemos aproximadamente el 80% de esos problemas, los mejores modelos actuales el 31%. Es muy probable que en los próximos meses este porcentaje siga creciendo.
La razón de la brecha es técnica…y profunda. Los modelos basados en Transformers son “motores de interpolación”. Son capaces de navegar dentro del espacio de lo conocido (sus datos de entrenamiento) y encontrar puntos medios con gran precisión. Pero el razonamiento real requiere extrapolación: la capacidad de tomar conceptos conocidos y aplicarlos en situaciones completamente inéditas.
Acá es donde se nota la falta de un cuerpo y de experiencia física: al no tener “grounding” o anclaje en el mundo real, les cuesta entender principios básicos de causalidad que para un humano son intuitivos.
Más allá de la predicción
Investigaciones recientes sugieren que incluso cuando los modelos parecen razonar, a menudo están desplegando heurísticas superficiales. Un estudio de 2024 sobre el rendimiento en ARC mostró que los modelos tienden a fallar cuando se introducen variables irrelevantes o cambios menores que no deberían afectar la lógica subyacente, mostrando que no están siguiendo un pensamiento robusto, sino replicando la “forma” de una respuesta lógica.
Lo que parece una crítica en realidad es una distinción necesaria: los LLMs operan en un régimen cognitivo diferente al humano, y entederlo nos permite diseñar mejores sistemas. El futuro inmediato probablemente no pase sólo por hacer modelos más grandes, sino por arquitecturas híbridas.
Estamos viendo el surgimiento de sistemas que combinan la fluidez lingüística de los LLMs con módulos de razonamiento simbólico, búsqueda de programas o verificación formal. El objetivo es ambicioso: unir finalmente la capacidad de predicción estadística con la estructura del pensamiento lógico. Por ahora, pensar, en el sentido estricto de sintetizar soluciones nuevas ante lo desconocido, sigue siendo territorio humano.
Lecturas relacionadas en mi blog:
- De las palabras a los números: cómo la IA construye significado
- La ilusión de la continuidad: cómo la IA teje la memoria sin tener pasado
- Cerebros en frascos, anclajes, o porqué la IA necesita un cuerpo
Referencias
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903.
- Chollet, F. (2019). On the Measure of Intelligence. arXiv:1911.01547.
- Yao, S., et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601.
- Hu, S., et al. (2024). Reasoning Abilities of Large Language Models: In-Depth Analysis on the Abstraction and Reasoning Corpus. arXiv:2403.11793.